Maxwell : Nextflow using apache ignite
Created by Frank Schluenzen on Jan 26, 2020 22:35
The job submission script
A sample submission script could look like this:
#!/bin/bash
#SBATCH --time=0-02:00:00
#SBATCH --nodes=4
#SBATCH --partition=upex
#SBATCH --job-name=nextflow-ignite-single-nodes-4-280
#SBATCH --dependency=singleton
#SBATCH --output=nextflow-ignite-single-nodes-4-280.out
#SBATCH --tasks-per-node=1
#SBATCH --constraint=Gold-6240
export LD_PRELOAD=""
export NXF_VER=19.09.0-edge
export NXF_CLUSTER_SEED=$(shuf -i 0-16777216 -n 1)
export NXF_ANSI_LOG=false
export NXF_ANSI_SUMMARY=false
rm -rf .nextflow* $HOME/.nextflow* work outdir/*
rm -rf procdir; mkdir -p procdir
source /etc/profile.d/modules.sh
module load mpi/openmpi-x86_64
module load crystfel
report="${SLURM_JOB_NAME}.report.html"
num_images=$(ls -1 /beegfs/desy/group/it/ReferenceData/cxidb/ID-21/cxidb-21-run01[34]*/data1/LCLS*.h5 | wc -l)
URL="https://desycloud.desy.de/remote.php/webdav/Maxwell/nextflow/${SLURM_JOB_NAME}-${SLURM_JOB_ID}"
# process each image individually
np=1
ls -1 /beegfs/desy/group/it/ReferenceData/cxidb/ID-21/cxidb-21-run01[34]*/data1/LCLS*.h5 > procdir/files.to.process
splitlines=$(( $(cat procdir/files.to.process | wc -l) / $np ))
#
# Run workflow
#
start=`date +%s`
startdate=`date`
# start one ignite process per node
mpirun --pernode /software/workflows/nextflow/bin/nextflow run indexamajig.nf.single --in '/beegfs/desy/group/it/ReferenceData/cxidb/ID-21/cxidb-21-run01[34]*/data1/LCLS*.h5' -with-mpi -with-report $report
enddate=`date`
end=`date +%s`
runtime=$((end-start))
cat <<EOF
Summary:
------------------------------------------------------------------------------------------------------
JOB.............: $SLURM_JOB_NAME
JobID...........: $SLURM_JOB_ID
Partition.......: $SLURM_JOB_PARTITION
Nodes...........: $SLURM_JOB_NUM_NODES
Split by........: $np
Start...........: $startdate
End.............: $enddate
Time............: $runtime
Number of Images: $num_images
URL.............: https://desycloud.desy.de/index.php/apps/files/?dir=/Maxwell/nextflow/
------------------------------------------------------------------------------------------------------
EOF
#
# Upload results to desyloud
#
test=$(curl -s -n -X PROPFIND -H "Depth: 1" "https://desycloud.desy.de/remote.php/webdav/Maxwell/nextflow" | grep "200 OK" | wc -l)
if [[ $test -eq 0 ]]; then
curl -s -n -X MKCOL "https://desycloud.desy.de/remote.php/webdav/Maxwell/nextflow" > /dev/null
fi
curl -s -n -X MKCOL "$URL" > /dev/null
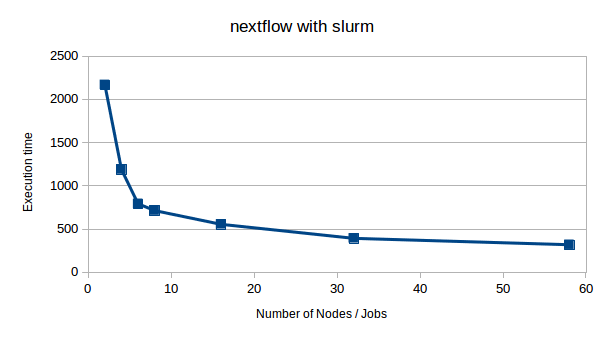
for file in indexamajig.nf.ignite nextflow-indexamajig.sh outdir/peaks.png outdir/cells.png nextflow-ignite-single-nodes-4-280.out $report ; do
if [[ -f $file ]]; then
target=$(echo $file | rev | cut -d/ -f1 | rev)
curl -s -n -T $file "$URL/$target" > /dev/null
fi
done
exit
The workflow declaration
Again that's just one possible way to define the workflow to illustrate some basics.
#!/home/schluenz/nextflow
nextflow.preview.dsl=2
process indexamajig {
maxForks 280
input:
path x
output:
file 'indexamajig.out'
script:
"""
out=\$(uuidgen)
echo "$x" | indexamajig -j 1 -i - -g /beegfs/desy/user/schluenz/Crystfel.Bench/5HT2B-Liu-2013.geom --peaks=hdf5 -o /dev/shm/\$out
cat /dev/shm/\$out > indexamajig.out
rm -f /dev/shm/\$out
"""
}
process peak_count {
maxForks 280
input:
file x
output:
file 'peak_count.out'
script:
"""
/home/schluenz/beegfs/Crystfel.Nextflow/peak_count.sh $x > peak_count.out
"""
}
process collect_index_output {
publishDir './outdir'
cpus 1
maxForks 1
input:
file '*.out'
output:
file 'indexamajig.all'
"""
cat *.out >> indexamajig.all
"""
}
process collect_peak_info {
publishDir './outdir'
cpus 1
maxForks 1
input:
file '*.out'
output:
file 'peaks.info'
"""
cat *.out >> peaks.info
"""
}
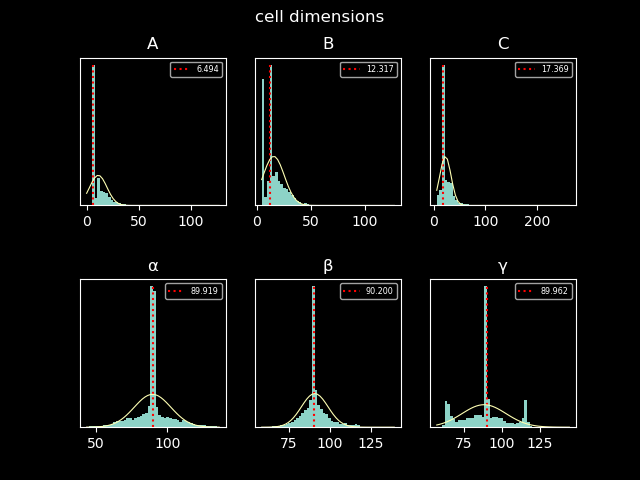
process simple_cell_plot {
publishDir './outdir'
cpus 1
maxForks 1
input:
path x
output:
file 'cells.png'
script:
"""
/beegfs/desy/user/schluenz/Crystfel.Nextflow/plot.cell.py $x
"""
}
process simple_peak_plot {
publishDir './outdir'
cpus 1
maxForks 1
input:
path x
output:
file 'peaks.png'
script:
"""
/beegfs/desy/user/schluenz/Crystfel.Nextflow/plot.peaks.py $x
"""
}
workflow {
/* run indexamajig and pipe to peak_count */
data = Channel.fromPath(params.in)
indexamajig(data) | peak_count
/* write output to slurm log and ./outdir/indexamajig.all */
collect_index_output(indexamajig.out.collect())
/* extract number of peaks and lattices and write to slurm log and ./outdir/peaks.info */
peakfile=Channel.fromPath('/beegfs/desy/user/schluenz/Crystfel.Nextflow/outdir/peaks.info')
collect_peak_info(peak_count.out.collect()) | (simple_peak_plot & simple_cell_plot)
}

{kind=link}
{kind=link}
{kind=link}
{kind=link}