Comsol v5.3 and newer natively support SLURM as a scheduler, which makes it very simple to launch Comsol batch-jobs on the Maxwell Cluster.
Note that comsol needs a substantial amount of disk-space, which will quickly exceed the quota of the home-directory. Relocating temporary folder might not be sufficient for complex models. see Comsol storage locations for additional options.
Comsol batch-jobs on a single node
When running on a single node you can let Comsol decide how many threads to use. Comsol will usually utilize all physical cores. A job template using a single node might look like this:
#!/bin/bash
#SBATCH --time=01:00:00
#SBATCH --nodes=1
#SBATCH --partition=allcpu
#SBATCH --constraint=[75F3|7402]
#SBATCH --job-name=comsol-test
unset LD_PRELOAD
# spostinfo collects some job-info
# a term_handler allows to collect the information even when the jobs gets preempted or times out
term_handler()
{
/software/tools/bin/spostinfo
}
trap 'term_handler' TERM
# collect some inital job-info like nodes and features
/software/tools/bin/sjobinfo
# setup environment
source /etc/profile.d/modules.sh
module load maxwell comsol/6.1
# comsol setup
infile=$PWD/test.mph
outfile=$PWD/test_out.mph
tmpdir=/beegfs/desy/user/$USER/tmpdir-$SLURM_JOB_ID
# run comsol
comsol batch -usebatchlic -inputfile $infile -outputfile $outfile -batchlog comsol.log -tmpdir $tmpdir
# cleanup
rm -rf /beegfs/desy/user/$USER/tmpdir-$SLURM_JOB_ID
exit
Comsol batch-jobs on multiple nodes
Using multiple nodes for comsol batch-jobs makes sense for reasonably large problems. Don't expect any speed-up when a single node takes just a few minutes. The overhead from launching multiple comsol-worker on multiple nodes (and the inter-process communication) can even increase the runtime compared to a single node.
When running Comsol on multiple nodes you have to give Comsol some hints how to distribute processes across nodes. With a simple test-case it was most efficient to start one comsol-worker per node (mpi-processes) and let comsol decide how many threads to use on each individual node (see below for some simple benchmarks). This can be most easily be achieved using --ntasks-per-node=1.
#!/bin/bash #SBATCH --time=01:00:00 #SBATCH --nodes=4 #SBATCH --partition=allcpu #SBATCH --constraint=[75F3|7402] #SBATCH --job-name=comsol-test #SBATCH --ntasks-per-node=1 unset LD_PRELOAD source /etc/profile.d/modules.sh module load maxwell comsol/6.1 infile=$PWD/test.mph outfile=$PWD/test_out.mph tmpdir=/beegfs/desy/user/$USER/tmpdir-$SLURM_JOB_ID mkdir -p $tmpdir # set storage options csstorage="-autosave off -tmpdir $tmpdir" # run comsol with INTEL MPI comsol batch -mpibootstrap slurm -usebatchlic -inputfile $infile -outputfile $outfile -batchlog comsol.log $csstorage -mpiroot /opt/intel/2022/oneapi/mpi/latest # cleanup rm -rf /beegfs/desy/user/$USER/tmpdir-$SLURM_JOB_ID exit
For large simulation it might become necessary to set the number of cores and threads explicitly. It seems however in most cases beneficial to use a small number of MPI-processes:
NP=4 NNHOST=2 NN=$(($SLURM_NNODES*$nnhost)) comsol batch -mpibootstrap slurm -usebatchlic -np $NP -nnhost $NNHOST -nn $NN -inputfile $infile -outputfile $outfile -batchlog comsol.log -tmpdir $tmpdir # # nn: total number of comsol-instances. # nnhost: number of comsol-instances per computer. nn should be $SLURM_NNODES*nnhost # np: number of threads each comsol instance uses. np*nnhost should be smaller than the number of physical cores per computer. # nodes: number of computers requested via slurm: #SBATCH -N <nodes>
Submitting a batch job from the GUI
It's fairly easy to submit a batch job directly from the COMSOL GUI. A detailed description can be found under https://www.comsol.com/blogs/how-to-run-on-clusters-from-the-comsol-desktop-environment/. A simple example based on the "vibrating deep beam tutorial":
You need to enable cluster computing on a "per study" basis. So right click on a study in your model and enable cluster computing. |
Select "User controlled", choose SLURM as the scheduler, set the partition (Queue name) and don't forget to tick "Use batch license". Don't specify a User. |
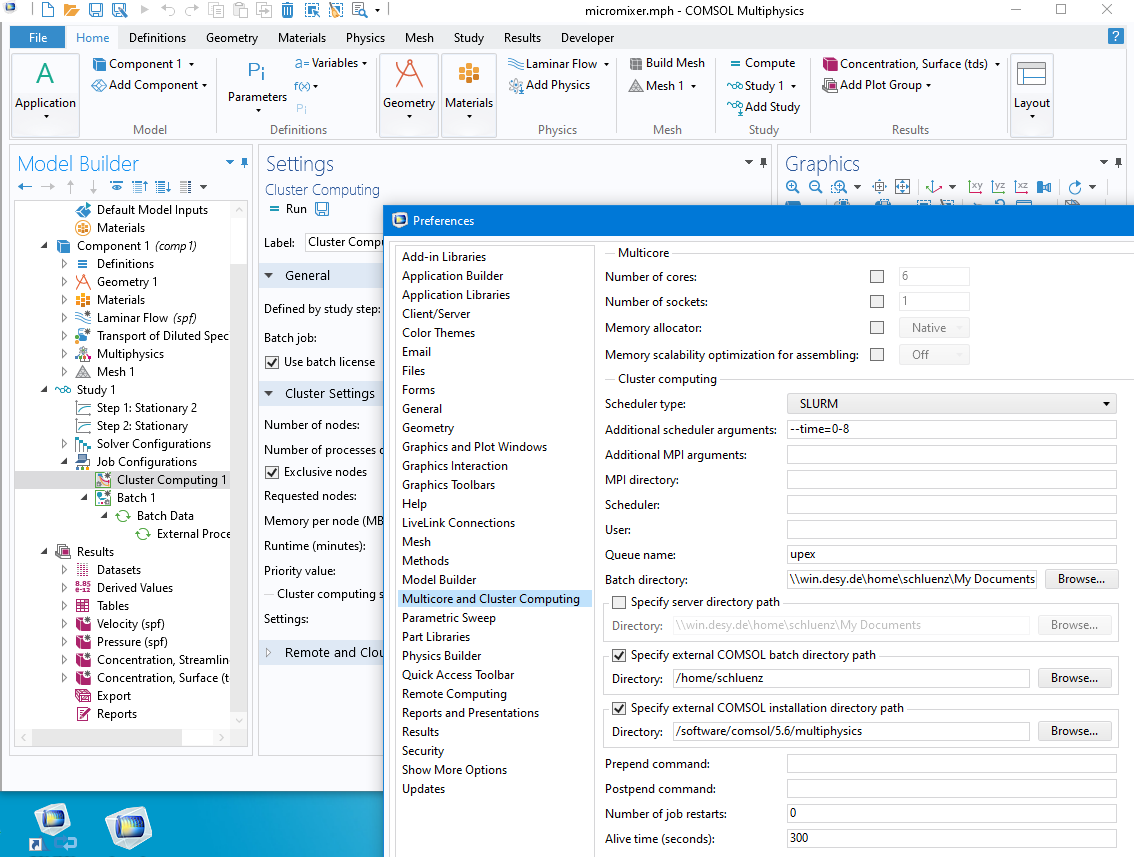
Note: the default runtime of jobs is usually 1 hour. Setting a different timelimit and possibly other batch parameters, you have to switch to "Preferences controlled" cluster setup, and set the preferences for "Multicore and Cluster Computing" as shown on the right. In that example, a runtime of 1 day and a constraint using only EPYC nodes has been. Make sure that entries for Scheduler and User are empty! |
|
Once your job is running you can detect the job with the squeue command as shown. scontrol show job <jobid> is very handy, as it will expose the command used by comsol to launch the job. |
This particular example needs the STRUCTURALMECHANICS module. If a license is available, the GUI process will allocate the license. The batch job - if "use batch license" was selected - will only use the BATCH licenses. In case all STRUCTURALMECHANICS where in use when starting COMSOL you will see a couple of messages about no licenses available. You can still submit the batch job and consume the STRUCTURALMECHANICSBATCH license. No free STRUCTURALMECHANICS license needed. |
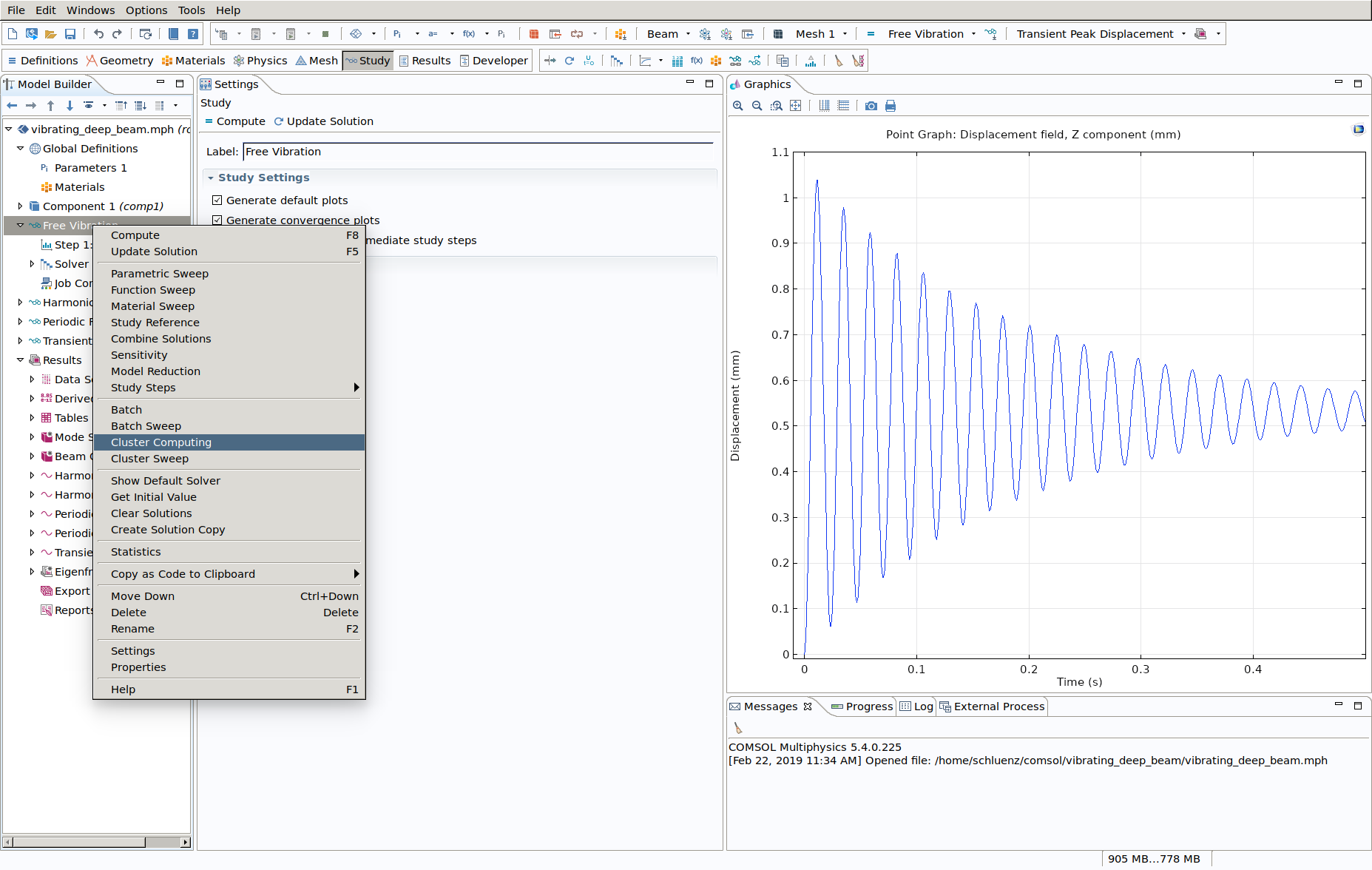
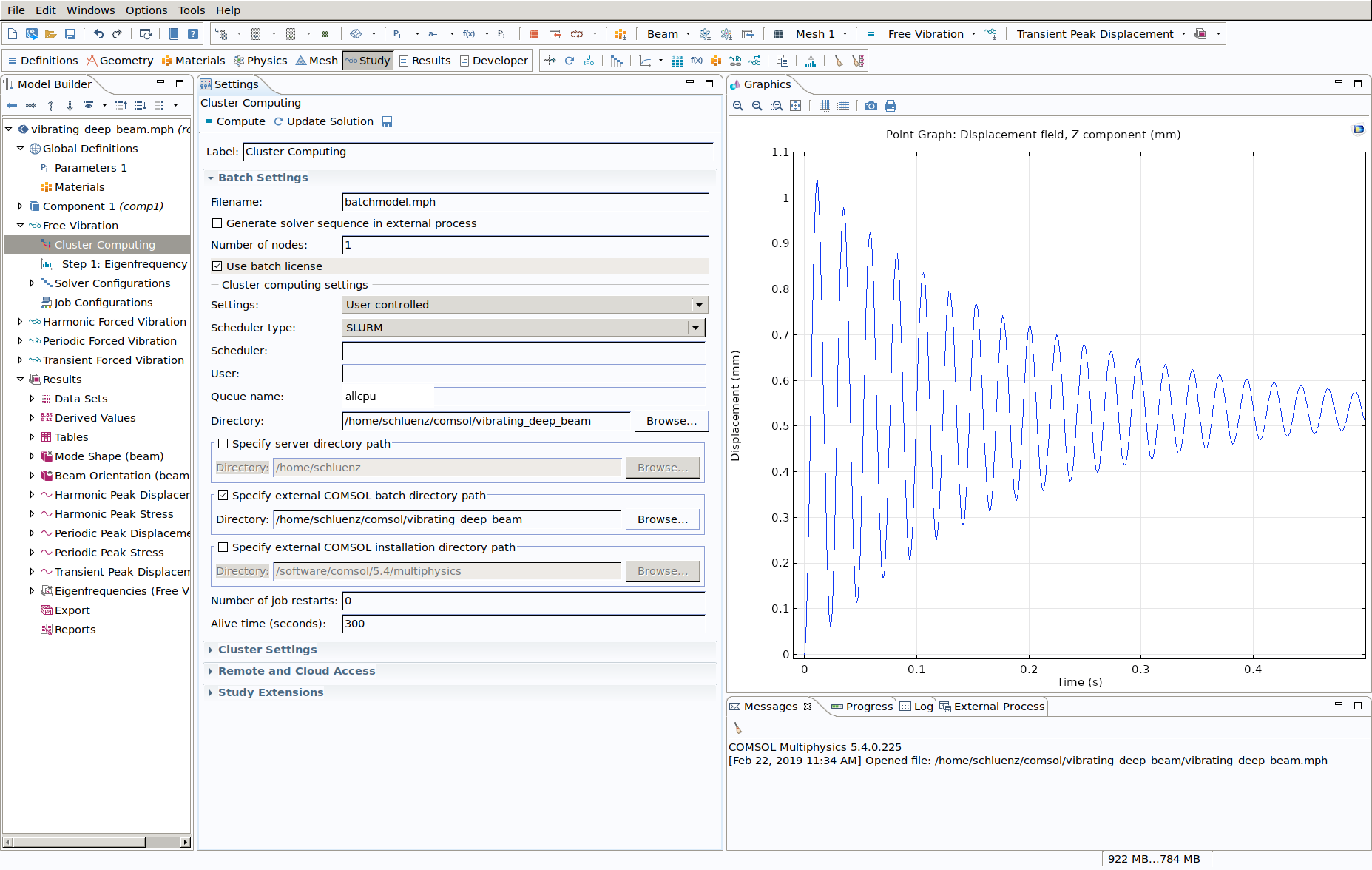
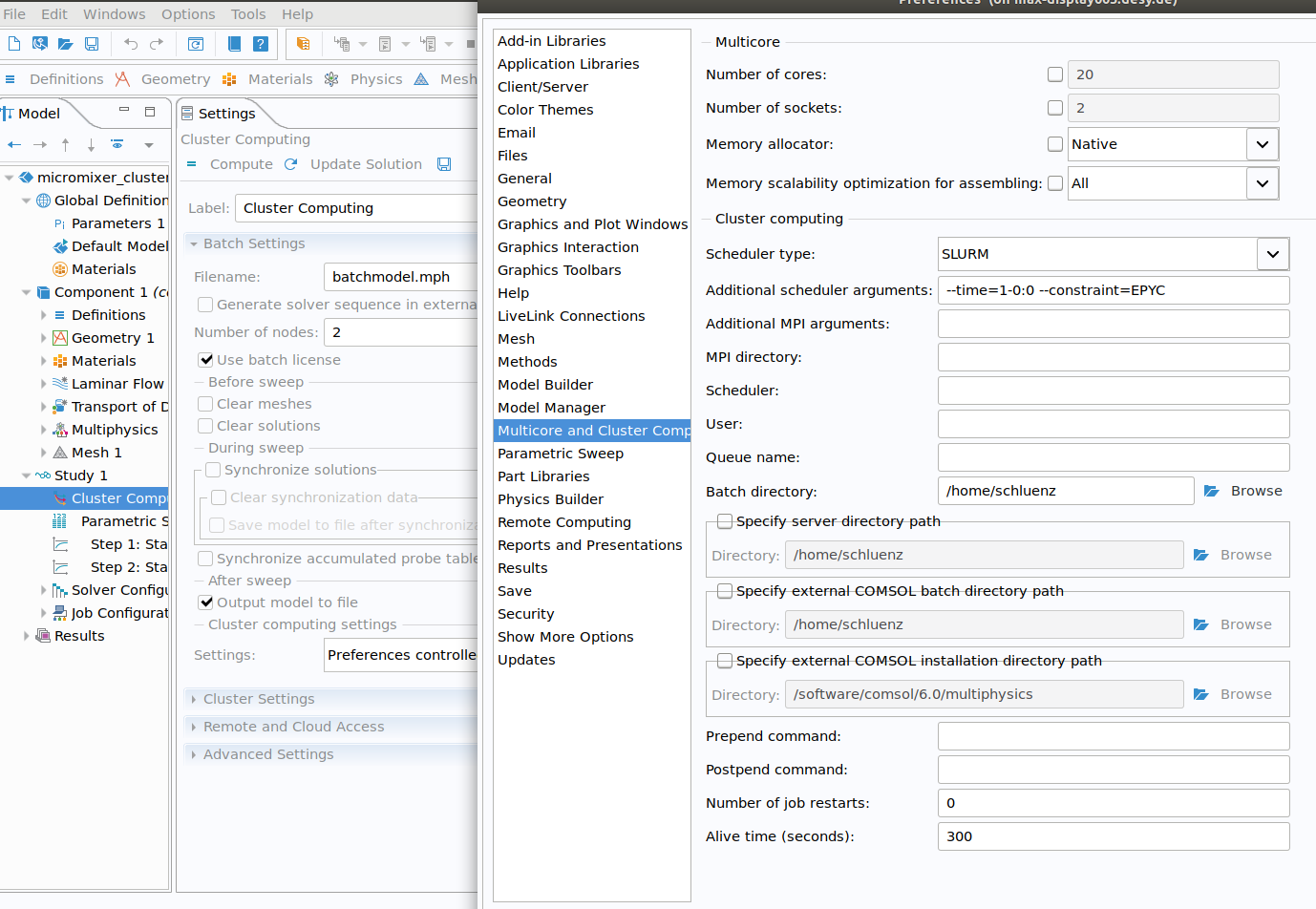
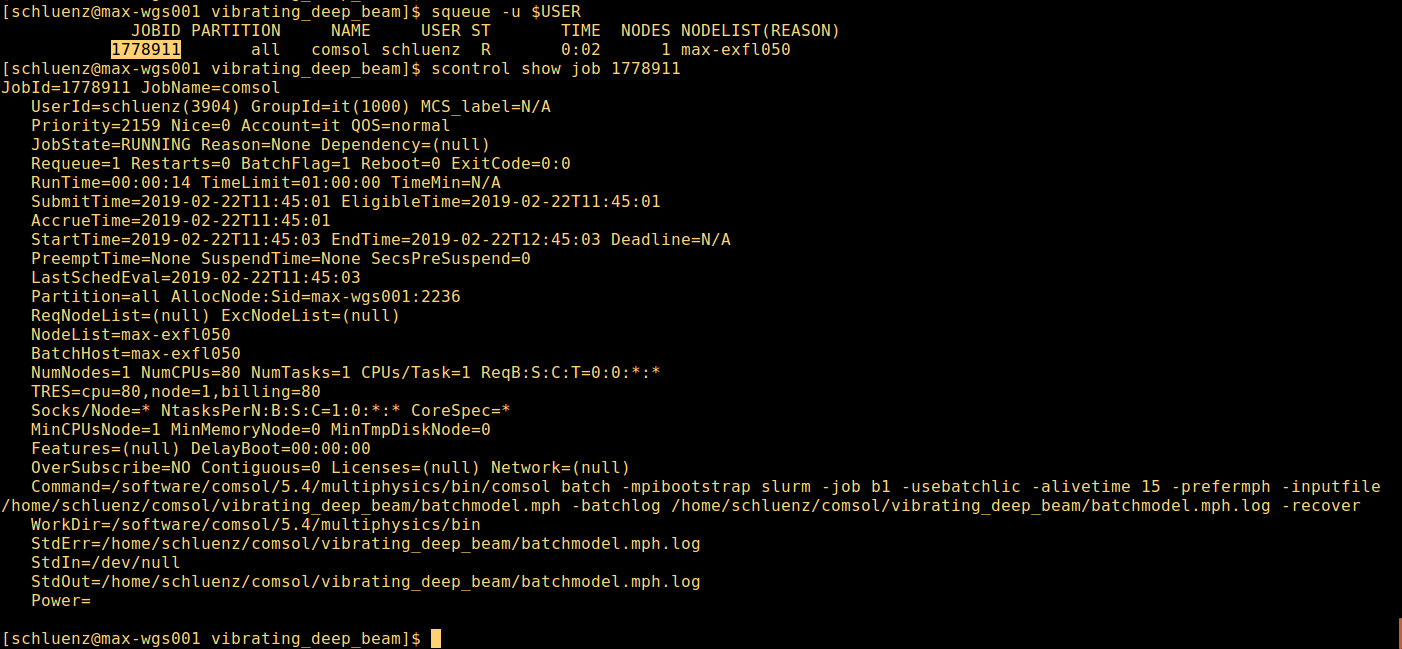
COMSOL remote configuration
It seems possible to run comsol for example from a Windows PC which is not directly connected to the maxwell cluster.
First you need to generate a public/private keypair and add the public key to ~/.ssh/authorized_keys on maxwell. Instructions can be found for example at https://www.ssh.com/academy/ssh/putty/windows/puttygen.
To submit a comsol batch job from the remote PC, follow the instructions from COMSOL: https://www.comsol.com/blogs/how-to-run-on-clusters-from-the-comsol-desktop-environment/
The configuration might look like this:
|
|
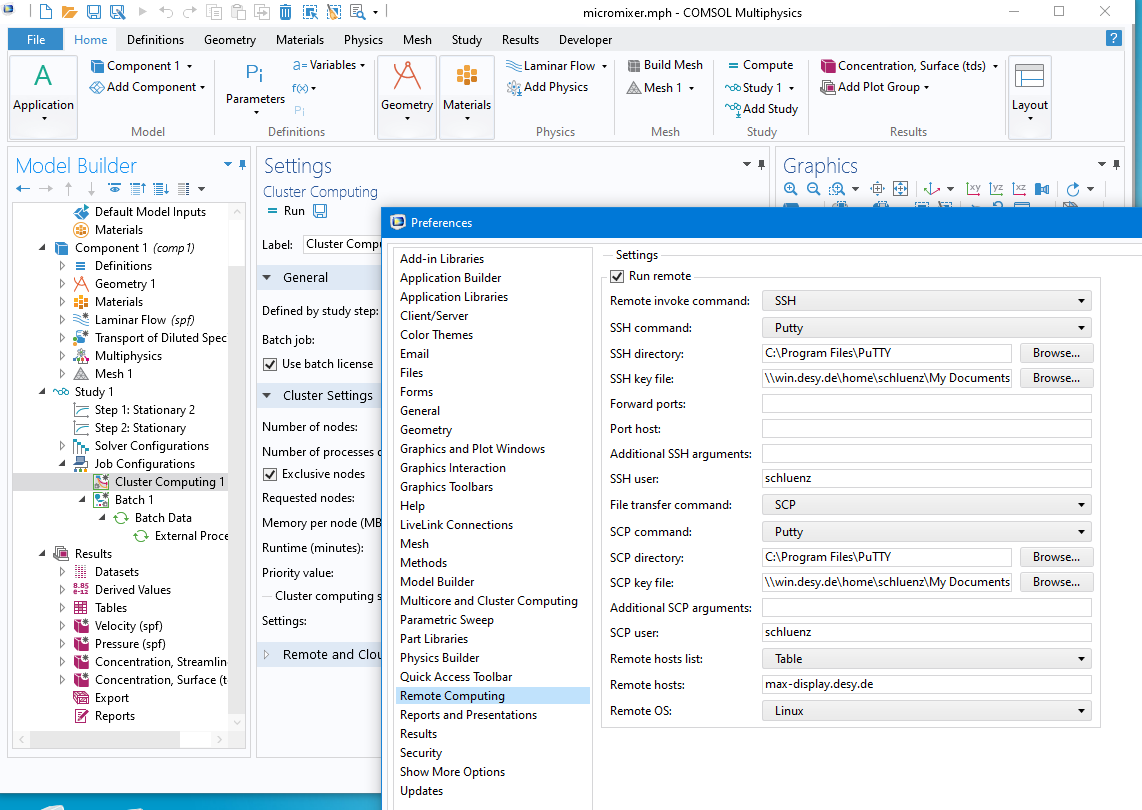
You might need to adjust paths.
COMSOL data storage
COMSOL stores substantial amount of data per default in $HOME/.comsol. It contains "recovery points" which can become quite large, and can easily exceed the 30G limit of the Home-Directory. It might hence be advisable to move .comsol to a custom location. Without a running comsol job one could simply:
- rm -rf $HOME/.comsol
- mkdir -p /beegfs/desy/user/$USER/.comsol
- ln -s /beegfs/desy/user/$USER/.comsol $HOME/.comsol
If you don't have a /beegfs/desy/user/$USER folder create one using the mk-beegfs command. Alternatively have a look at Comsol storage locations
COMSOL Benchmarks
Short COMSOL test-job
The following table shows the runtime (in seconds) for the comsol job depending on the number of nodes used, and the number of MPI processes per node (--ntasks-per-node=<n>).
- For a single node no MPI was used.
- Constraint was set to 75F3 (AMD EPYC) to use more or less the same hardware for all runs.
- Each run was repeated 5 times, but the first run omitted from the average runtime. The first run is always slower due to the application loaded from disk rather than being in GPFS cache.
| #MPI processes per node | |||||
|---|---|---|---|---|---|
| #nodes | 1 | 2 | 4 | 8 | 16 |
| 1 | 243 | - | - | - | - |
| 2 | 234 | 260 | 294 | 307 | 441 |
| 4 | 208 | 212 | 239 | 253 | 327 |
| 8 | 194 | 195 | 206 | 212 | 250 |
Extended COMSOL test-job (5_diel_disc_iterative_largesize.mph)
Same procedure for a much more complex, which takes several hours on a single node ( I think the model came from one of the Comsol tutorials)
| #MPI processes per node | |||||
|---|---|---|---|---|---|
| #nodes | 1 | 2 | 4 | 8 | 16 |
| 1 | 22230 | - | - | - | - |
| 2 | 14150 | 13320 | 15520 | 20430 | - |
| 4 | 8970 | 9320 | 9560 | 12950 | 16120 |
| 8 | 6340 | 6590 | 7050 | 7710 | 9260 |
| 16 | 6130 | 5480 | 5490 | 6080 | 6470 |
Information from Comsol Multiphysics support
The amount of speedup you can expect from a parallel computation on several cluster nodes highly depends on the type of problem and the model
size. The shell_and_tube_heat_exchanger example model has around 600k DOFs out of the box, which is not very much when it comes to cluster usage. So a speedup of only ~Factor 2 over a workstation is expected for such a model. In some cases we see even worse performance gains for models below 1M degrees of freedom on clusters, up to the point where a fast workstation outperforms a cluster. For larger models the gain is usually more significant.
As for the MPI version: Pointing to a newer MPI version via -mpiroot is our recommended fix (see https://www.comsol.com/support/knowledgebase/1298)