Cloning a page confluence page tree (without content) is not too difficult using the confluence rest api. A simple bash script is pasted below. It requires jq to be installed (e.g. with pip https://pypi.org/project/jq/), and a few confluence functions to be present.
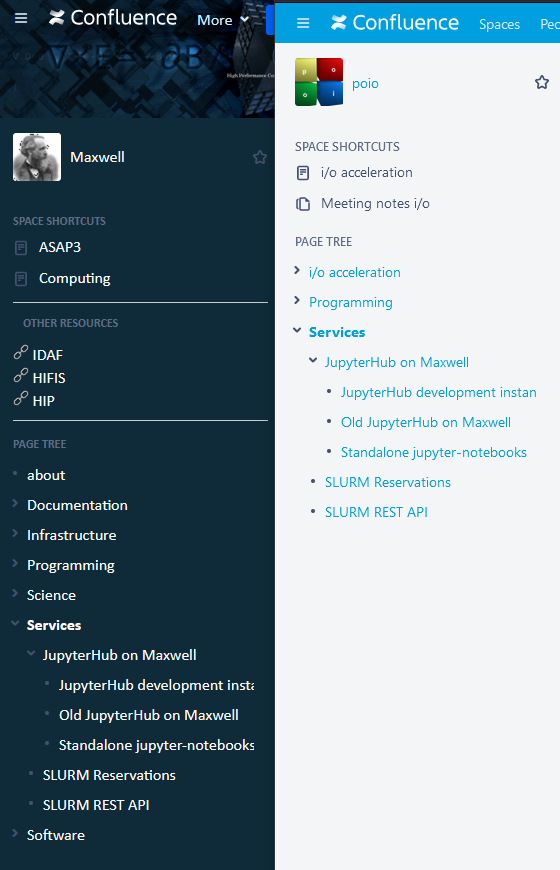
The sample script creates a copy of Services in Maxwell space to Services in a space named poio. The script surely is buggy and incomplete but might give an idea how to. Have a look at https://developer.atlassian.com/server/confluence/confluence-rest-api-examples/ for more and better examples. The python API (https://atlassian-python-api.readthedocs.io/confluence.html) would be an interesting alternative.
The sample script
#!/bin/bash
# confluence.functions can be found below
source $HOME/home-dir/confluence/confluence.functions
export CF_COOKIE=$HOME/.ssh/confluence/confluence.cookie
cf_authorize
#
# recursively walk down a page tree and create the pages
#
treewalk() {
local childs
local pageID
local child
local n
local parent
local page
local parentID
page="$1"
parent="$2"
pageID=$( cf_get_pageID $spaceKey "$(echo "$page" | tr -d '"')" )
parentID=$( cf_get_pageID $newSpace "$(echo "$parent" | tr -d '"')" )
childs=$(curl -s -b $CF_COOKIE -X GET "https://confluence.desy.de/rest/api/content/$pageID/child/page?expand=children.page" | python -mjson.tool )
n=0
child="x"
while [[ "$child" != "null" && "x$child" != "x" ]]; do
child=$(echo "$childs" | jq ".results[$n].title")
c="$(echo $child | tr -d '"')"
if [[ "$child" != "null" ]] ; then
if [[ $parentID -eq 0 ]]; then
echo " creating top-level page $child"
cf_create_page $newSpace "$c" > /dev/null 2>&1
elif [[ $parentID -gt 0 ]]; then
echo " creating $child as child of $parent"
cf_create_child_page $newSpace $parentID "$c" > /dev/null 2>&1
fi
sleep 3 # might not be necessary ...
treewalk "$child" "$child"
fi
n=$(($n+1))
done
}
#
# original space: spaceKey
# original page: oldParent
#
spaceKey=MXW
oldParent=Services
pageID=$( cf_get_pageID $spaceKey "$oldParent" )
if [[ "$pageID" == "null" || "$pageID" == "0" ]]; then
echo " Page $oldParent does not exist in space $spaceKey"
echo " Check space https://confluence.desy.de/display/$spaceKey"
echo " abort"
exit
fi
#
# new space: newSpace
# new toplevel page: newParent
#
newSpace=POIO
newParent=Services
spacePageID=$(cf_get_pageID $newSpace "" | awk '{print $1}')
newPageID=$( cf_get_pageID $newSpace "$newParent" )
if [[ "$newPageID" == "null" || "$newPageID" == "0" ]]; then # page doesn't exist yet, create it nested under toplevel page
cf_create_child_page $newSpace $spacePageID "$newParent" > /dev/null 2>&1
sleep 3 # just in case
checkID=$( cf_get_pageID $newSpace "$newParent" )
if [[ $checkID -eq 0 ]]; then
echo " Page creation for $newParent in $newSpace failed "
echo " abort"
else
echo " Created page $newParent "
fi
else
echo " Page $newParent exists. PageID: $newPageID"
fi
treewalk "$oldParent" "$newParent"
exit
The confluence.functions simple utilities:
# simple confluence functions
#
# check if jq exists
#
which jq > /dev/null 2>&1
if [[ $? -gt 0 ]]; then
echo "nothing done - install jq !"
exit
fi
#
# check if cookie is still valid; get new one if not
# private_url must be an(y) existing page which requires a login to access!
#
private_url="https://confluence.desy.de/display/~schluenz/Infiniband"
function cf_authorize {
test=$( curl -b $CF_COOKIE --silent "$private_url" | wc -l )
if [[ $test -gt 20 ]]; then
echo " Cookie still valid"
else
echo " Cookie expired! "
curl -u $USER -c $CF_COOKIE "https://confluence.desy.de/dologin.action" -s --output /dev/null
fi
}
#
# get version of page, set to 0 if page doesn't exist
#
function cf_get_pageV {
cfspaceKey=$1
title=$(echo "$2" | sed 's| |%20|g')
#title="$2"
current=$(curl -s -b $CF_COOKIE -X GET "https://confluence.desy.de/rest/api/content?title=${title}&spaceKey=${cfspaceKey}&expand=version" | python -mjson.tool | jq '.results[].version.number')
[ "x$current" == "x" ] && current=0
echo $current
}
#
# create new page
#
function cf_create_page {
cfspaceKey=$1
#title=$(echo "$2" | sed 's| |%20|g')
title="$2"
cat <<EOF>upload.tmp
{"type":"page","title":"${title}","space":{"key":"${cfspaceKey}"},"body":{"storage":{"value":"","representation":"storage"}}}
EOF
curl -s -b $CF_COOKIE -X POST -H 'Content-Type: application/json' -d @upload.tmp "https://confluence.desy.de/rest/api/content" | python -mjson.tool
}
#
# create new child page -not tested once!
#
function cf_create_child_page {
cfspaceKey=$1
parentID="$2"
#title=$(echo "$3" | sed 's| |%20|g')
title="$3"
cat <<EOF>upload.tmp
{"type":"page","title":"${title}","ancestors":[{"id":${parentID}}],"space":{"key":"${cfspaceKey}"},"body":{"storage":{"value":"","representation":"storage"}}}
EOF
curl -s -b $CF_COOKIE -X POST -H 'Content-Type: application/json' -d @upload.tmp "https://confluence.desy.de/rest/api/content" | python -mjson.tool
}
#
# get pageID, return 0 if page doesn't exist
#
function cf_get_pageID {
cfspaceKey=$1
#title="$2"
title=$(echo "$2" | sed 's| |%20|g')
cfpageID=$(curl -s -b $CF_COOKIE -X GET "https://confluence.desy.de/rest/api/content?title=${title}&spaceKey=${cfspaceKey}&expand=version" | python -mjson.tool | jq '.results[].id' | tr -d '"' )
[ "x$cfpageID" == "x" ] && cfpageID=0
echo $cfpageID
}
#
# upload a json-file
#
function cf_uploadF {
cfpageID=$1
file=$2
curl -s -b $CF_COOKIE -X PUT -H 'Content-Type: application/json' -H 'Accept: application/json' -d @${file} "https://confluence.desy.de/rest/api/content/${cfpageID}" | python -mjson.tool
}
#
# convert html to json and upload
#
function cf_uploadFHTML {
cfspaceKey=$1
title="$2"
cfpageID=$3
newV=$4
file=$5
# >&2 echo "$title $cfspaceKey $cfpageID $newV $file"
cat <<EOF>upload.tmp
{"id":"${cfpageID}","type":"page", "title":"${title}","space":{"key":"${cfspaceKey}"},"body":{"storage":{"value":"
EOF
cat $file >> upload.tmp
cat <<EOF>>upload.tmp
","representation":"storage"}}, "version":{"number":${newV}}}
EOF
cat upload.tmp | tr -d '\n' > upload.tmp3
cf_uploadF $cfpageID upload.tmp3
# rm -f upload.tmp*
}
The output of the script:
Cookie still valid Created page Services creating "JupyterHub on Maxwell" as child of Services creating "JupyterHub development instance" as child of "JupyterHub on Maxwell" creating "Old JupyterHub on Maxwell" as child of "JupyterHub on Maxwell" creating "Standalone jupyter-notebooks" as child of "JupyterHub on Maxwell" creating "SLURM Reservations" as child of Services creating "SLURM REST API" as child of Services
The two page trees after running the script